O que é uma Solução de Apoio à Decisão?
Solução de Apoio à Decisão (SAD) também conhecido Business Intelligence ou Business Analytics, é a especialidade da e-Setorial: transformar dados em informações úteis para auxiliar a tomada de decisões. A partir da integração de dados oriundos de diversas fontes, é possível organizá-los, categorizá-los e filtrá-los em uma única plataforma. Oferecemos ferramentas visuais intuitivas que permitem a análise e compartilhamento das informações com sua equipe, assegurando a confiabilidade da escolha do gestor.

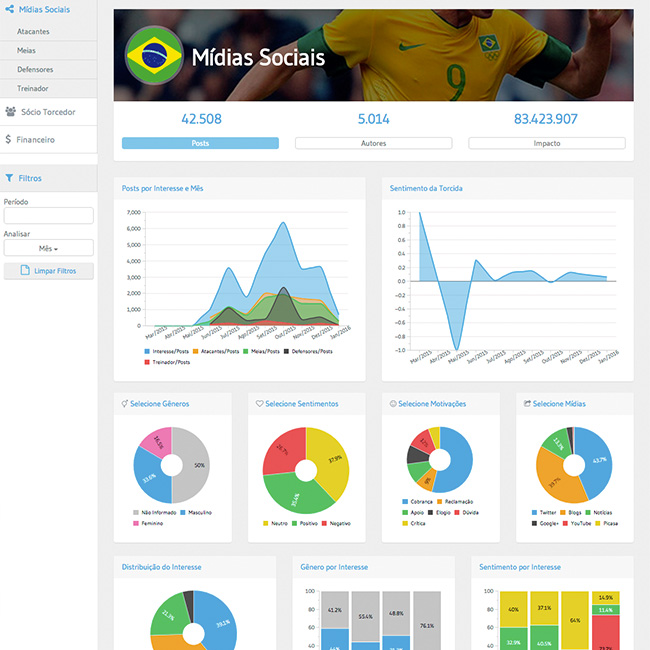
(modelos de dashboards oferecidos pela e-Setorial)
Confira o Workflow das nossas Soluções de Apoio à Decisão.
Não entendeu muito bem? A gente exemplifica. O seguinte caso aconteceu com uma distribuidora de carros da Toyota:
No final dos anos 90, a empresa enfrentou grandes problemas em sua cadeia de operações. O custo de armazenamento de carros se elevou e ela não estava mais conseguindo fornecer o produto a tempo para seus clientes. Utilizava computadores que geravam uma quantidade enorme de dados e relatórios que não eram utilizados estratégicamente porque nem sempre eram exatos e muitas vezes eram fornecidos tarde demais - o que atrasava a tomada de decisões.
Uma nova CEO foi contratada. Ela identificou algumas soluções: primeiro, a necessidade de um Data Warehouse - um repositório central de dados, organizado e de fácil acesso. Segundo, a necessidade de implementação de ferramentas de software para efetuar a manipulação desses dados. O novo sistema implantado infelizmente não funcionou de maneira correta: a entrada de dados históricos incluiam anos de erros humanos que foram desapercebidos, dados duplicados, inconsistentes e falta de importantes informações. Tudo isso gerou análises e conclusões precipitadas sobre o funcionamento da distribuidora.
Apenas em 1999 a empresa resolveu implantar uma plataforma de Business Intelligence. Em questão de dias o sistema apresentou bons resultados. Por exemplo, descobriram que a empresa era cobrada duas vezes por um envio especial por trem (um erro de US$ 800.000). Entre 2001 e 2005, o volume de carros negociados aumentou em 40%, o tempo de trânsito foi reduzido em 5%. Esses e vários outros benefícios ajudaram a Toyota a alcançar as maiores margens de lucro no mercado automotivo desde 2003, e estão aumentando consistentemente a cada ano desde então. Além disso, um estudo realizado pela IDC Inc. em 2011, indicou que a instituição alcançou, naquele ano, um retorno de pelo menos 506% sobre o investimento em BI.
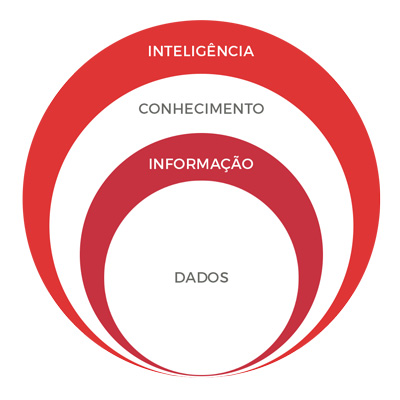
Esse é apenas um dos inúmeros casos que ilustram a eficiência dessas soluções capazes de integrar e interpretar dados, transformando-os, de alguma forma, em Informação relevante ao seu negócio, possibilitando, com a devida análise, a criação de Conhecimento. Através da utilização e da gestão deste conhecimento nasce a Inteligência.
Mais de 15 anos passaram desde que a Toyota adotou o BI. Atualmente, geramos mais de 2.5 quintilhões de bytes de dados diariamente, sendo que 90% dos existentes hoje foram criados nos últimos 2 anos. A tendência é que esse número cresça de uma forma cada vez mais rápida.
E você, o que vai fazer com os seus dados?