5 transformações que a internet causou ao mundo dos negócios
![]()
Qualquer pessoa com acesso a aparelhos eletrônicos inteligentes pode notar que estamos em uma época onde a internet está sendo introduzida em praticamente tudo que utilizamos. Há quem diga que estamos próximos de uma "internet dos seres humanos", não apenas "internet das coisas".
Abaixo listamos 5 mudanças que essa evolução causou ao mundo dos negócios.
1) Monitoramento
Empresas agora podem avaliar melhor como seus consumidores utilizam seus produtos através do monitoramento de diversas redes. Isso permite uma estimativa mais precisa do ciclo de vida de um produto. É quase como se as empresas pudessem monitorar equipamentos ou produtos em sua casa tão facilmente como se podem controlá-los em seus laboratórios.
2) Altas expectativas
Os consumidores sabem que estão fornecendo às empresas mais informações do que nunca. Isso resulta em clientes com grande expectativa de qualidade, valor e suporte contínuo.
![]()
3) Presença online
Independente do tamanho da sua empresa, seus clientes esperam encontra-lo online. Mesmo que vejam sua loja física na cidade, sem um site acessível através de uma pesquisa no Google, você está na contra mão. Você quer continuar competindo na economia do século 21? Capriche na identidade visual e confie em uma empresa de marketing digital para desenvolver conteúdo para seu site. Dê para sua empresa a imagem que ela merece.
4) Suporte e solução de problemas
Caso tenha um problema com seu produto/serviço, o cliente espera que você saiba lidar com isso, que forneça uma solução e que tenha uma equipe de técnicos de apoio 24 horas por dia. Sem um site projetado para resolver os problemas de seus clientes de forma rápida, você vai perder para a concorrência.
5) Análise de Big Data
As empresas atuais geram internamente uma grande variedade de dados e também têm acesso a uma infinidade de informações na grande rede, em publicações e em redes sociais. A análise desses dados tornou-se um dos principais desafios para quem busca se posicionar no mercado.
Isso significa que qualquer ação se tornou muito mais competitiva e eficaz no momento de envolver o público-alvo. Além disso, essas informações podem ser utilizadas para melhorar a experiência dos clientes: as empresas agora podem compreender exatamente o que eles estão procurando, quando e como preferem fazer realizar suas tarefas diárias.
A especialidade da e-Setorial é transformar dados em informações úteis para auxiliar a tomada de decisões. Saiba mais sobre as nossas Soluções de Apoio à Decisão clicando aqui.
 Variedade
Variedade Saberemos exatamente o que experar do próximo iPhone apenas quando a Apple fizer seu anúncio oficial. Mas o Analista de KGI (Key Goal Indicator ou Indicadores Chave de Sucesso)
Saberemos exatamente o que experar do próximo iPhone apenas quando a Apple fizer seu anúncio oficial. Mas o Analista de KGI (Key Goal Indicator ou Indicadores Chave de Sucesso)
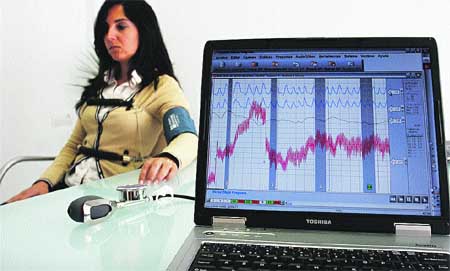 Cada vez mais coletamos dados sobre nossos costumes do dia a dia. Isso torna mais difícil para alguém mentir sem ser descoberto. O Big Data e as inovações analíticas são capazes de dizer se você está dizendo ou não a verdade.
Cada vez mais coletamos dados sobre nossos costumes do dia a dia. Isso torna mais difícil para alguém mentir sem ser descoberto. O Big Data e as inovações analíticas são capazes de dizer se você está dizendo ou não a verdade.